Analyzing LFFD architecture, a one-stage object detection pipeline to detect faces LFFD is an anchor free face detector and belongs to the one-stage category of object detection mechanisms Receptive Fields (RFs) are deployed as natural “anchors” Unlike in fully connected networks, where the value of each unit depends on the entire input to the network, a unit in convolutional networks only depends on a region of the input.
This region in the input is the receptive field for that unit. Source:Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
✏️✏️✏️ Receptive Field (ERF): Consider the scenario above: (visualisation on lower left) 💡💡💡 If you notice, the receptive field (RF) of the first neuron belonging to the first convolutional filter (green 💚) is ** a 3x3 patch of the input image(blue 💙). The output feature map consists of 9 neurons/features (each neuron will have a RF of 3x3) Similarly, the receptive field (RF) of the first neuron belonging to the second convolutional filter (orange 🧡) is ** a 7x7 patch of the input image(blue 💙). The output feature map consists of 4 neurons/features (each neuron will have a RF of 7x7) With this intuition we can state that the neurons in shallow layers have small RFs and those
in deeper layers have large RFs. 📔 For mathematical equations you could refer to following link However, one thing that the authors (Luo, Wenjie et al) of the paper "Understanding the Effective Receptive Field in Deep Convolutional Neural Networks" notice is that not all pixels in the receptive field contribute equally to the output unit’s response The pixels that actually contribute to learning is what we call the Effective Receptive Field (ERF) If you notice this is clearly visible by the pixels that are repeatedly covered by the kernel as it is convolved with the input image. The edge pixels are convolved lesser number of times as compared to the centre pixels. (You could try this out in your head and it will make more sense ) Thus the ERF plays an important role when it comes to learning. ✏️✏️✏️ The paper treats large and tiny faces differently. The assumption is that tiny faces are more difficult to recognize as compared to larger faces. In order to capture tiny faces more contextual information is used to come to a conclusion As the paper states:- for tiny/small faces, ERFs have to cover the faces aswell as sufficient context information ✏️✏️✏️ Face detection falls under the category of object detection and the authors try to avoid the use of anchor boxes as in general object detection pipelines and use the receptive fields as natural anchors. Since faces have an aspect ratio of 1:1 kernels with width and height as 1 is used to generate square shaped RFs to detect faces. For the matching strategy, the RF box is matched to a ground truth (GT) box iff its center falls in the GT bbox, other than thresholding IOU ✏️✏️✏️ The network architecture is divided into 4 parts. The first two layers downsample the input with stride 4, stride 2 from each The LFFD Loss function is similar to an SSD Multibox Loss function. It consists of : -LFFD Paper review

Introduction:
Contents:
Receptive Field (RF) vs Effective

Receptive field (RF)
Effective Receptive field (ERF)
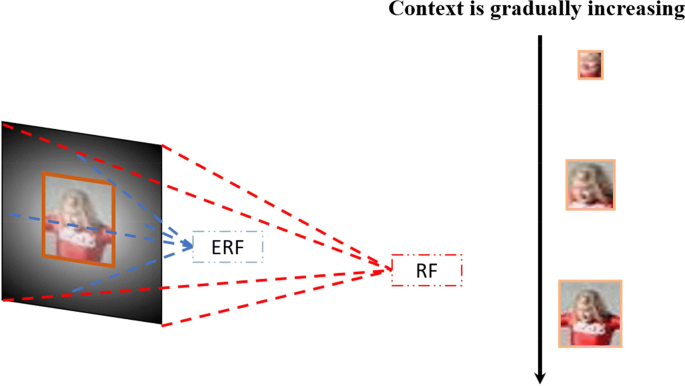
Large faces vs tiny faces
RFs as Natural "Anchor"
Network Architecture

Sources:
Code (under construction):
Implementation:
- negative_positive ratio : During the computation, by default most of the bboxes would belong to class 'background'. In order to avoid this imbalance, we keep a limit on the num of background bboxes that would be a part of the loss function (Try a value b/w 3 and 10)
